Hard drives fail, this is a fact. We talked in a previous article about how long hard drives, given optimal living conditions, will last and how many will have to be replaced.
Life however, is not always the cushy, climate controlled wonderland that hard drives like to live. It is violent and inconsistent, which leads to even shorter lives than what is dictated by MTBF.
So what are these factors that can lead to hard drive failures?
Movement, Generally Vibration
Vibration in datacenters is a very huge problem that most people don’t pay attention to. In a given rack, there are a LOT of moving parts: other hard drives are spinning, fans are spinning, and various things contribute to minute, but additive vibrations.
Try not to forget what a hard drive is; it’s a metal plate traveling between 5,400 and 15,000 RPM (that can mean up to 150 mph) at only a fraction of the thickness of a human hair away from the heads that are reading the data. It doesn’t take a massive amount of vibration to cause some serious problems when the heads are that close to the platters. What does that actually look like?
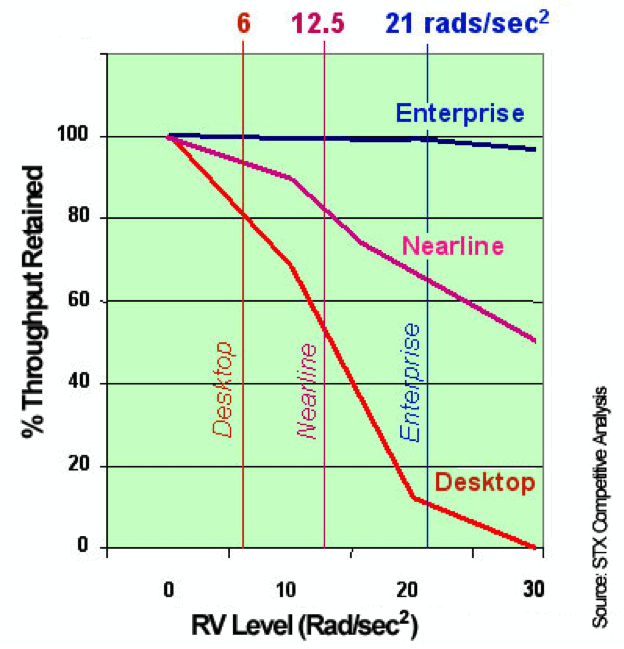
As an example, an average RAID enclosure will experience between 12 and 25 rad/sec in an average rack. Those numbers obviously mean nothing to us as normal humans, but think of it this way:
Acceptable tolerance on a Seagate desktop-grade 7.2k drive is about 6 rad/second, on an enterprise-grade 7.2k drive it’s about 12.5 rad/second, and on a true enterprise-grade drive 10/15k drive it is 21 rad/second. Once you start exceeding those tolerances, the performance drops significantly on the drives, and they are more likely to fail.
Other Causes for Hard Drive Failures
False Positives
This is what causes the most hard drive failures. The drive gives data back that is malformed or takes a little bit too long to respond, and the entire drive is marked as dead by the RAID controller. There are normally no efforts made to recover the drive or its data, rather the entire drive is marked as failed and a rebuild starts on the next drive.
Human Error
This causes far more failures than you might expect. Not all drive arrays blink orange when a drive has failed. This means someone must look in the controller, see the drive that has failed, and go replace it themselves. This is exacerbated by two things: multi-shelf arrays that have between two and 40 shelves on the array, and the fact that a lot of arrays start numbering drives at zero, rather than one. Simple counting in this case leads to the wrong drive being replaced, and the whole array being taken down hard.
Powering It Off
I’m sure this has never been experienced by anyone else in IT:
“We need to shut that server down to move it.”
“That server is a TANK, it has been on for eight years straight and has NEVER, not ONCE had a hardware issue!”
And then once it’s powered off and moved five feet, drives fail, fans won’t spin up, power supplies explode, all number of things go horribly awry. This is Newton’s first law in reality, folks: as long as they keep spinning, they want to keep spinning. Once they go still, they don’t want to move anymore.
The “Bathtub Curve”
This is a metric of failure that no storage manufacturer acknowledges publicly. This is the propensity for drive failures to occur as infant mortality or from old age. If you look at that on a graph, it looks like the cross section of a bathtub. This is what allows you to put in a brand new system and have one or two failures immediately, and then not have any failures for three years until suddenly there are six hard drives that fail within two months.
Environmental Concerns
As with all things electronic, temperature and humidity can have adverse effects on the life and prosperity of the equipment. Drives that don’t get cooled properly and drives that live in overly humid environments have their life shortened greatly.
This happens often in drive trays that aren’t designed properly to allow for airflow. You’ll notice that many drive trays have loads of holes and vents in the drive trays, but if you pull those drives out and look behind them there’s often a solid backplane that doesn’t allow any air to pass, which causes some drives to get very warm.
All of the above can lead to more drive failures in RAID arrays, which can lead to more rebuild times, which can leave an environment more exposed to performance issues and additional failures, which will be covered more in the next blog.