In modern IT, it’s easy to lose sight of fundamentals. We get so caught up in VMware, Exchange and SQL and we forget about the underlying building blocks of everything. Storage in particular can get a bit dodgy when you get down to the nitty gritty details of blocks, MFTs, file records, deduplication and compression.
If you need a primer to remember the details of these, here’s a simple analogy to help you remember.
Storage is Like a Book
For starters, storage is just a bunch of ones and zeros, like a book is just a bunch of letters. If either of them are out of order, they mean nothing if you try to read them. When we make thoughts to write a book (or read it), we don’t operate letter by letter (after second grade), we do it word by word. These words are the storage equivalency of a block. An operating system doesn’t just read or write ones and zeros one by one, it combines them into units called blocks and then writes/reads them all at once.
There is a key differentiation here: unlike words, all blocks are of a uniform size, determined when the volume is first formatted, and can never be changed later. If the data is too small, zeros fill out the rest of the block. If too big, the data is broken up into multiple blocks. It would be as if the English language only allowed four-letter words. Anything longer would have to be broken up into multiple words, and anything shorter would just have a bunch of As after it.
These blocks are then combined to create files. A file is like a sentence (or chapter depending on its size). Multiple words going together to create a single cohesive idea that conveys a point. But how do we find one of these cohesive ideas without reading through the entire book? We have an index. This index is like the master file table in NTFS. It’s a table that stores where every file exists on the drive. If you lose the index, you can still get to the stuff in the book but you have to scan the whole book to find what you want. It’s much the same with the file allocation table. If you lose it, the data is technically still there, but finding it requires scanning the whole drive to figure out what’s there.
These indices store a very small amount of data about the files, traditionally only 512 bytes. Thinking of that in terms of the book analogy, it wouldn’t matter how many times an idea was referenced in a book, the index would only be able to store a few (let’s say five) references to the idea. As storage has gotten larger and larger (longer and longer books), these 512-byte references started to become prohibitive. All the necessary references to a thought couldn’t be stored in that 512 bytes, so manufacturers have gone to 4K (4096 byte) file records in the MFT so that much more metadata can be stored about that file. Of course, that also means our index is now using much more of the book in order to be more precise.
Modern Practical Implications
So why does any of this matter recently? Why should you care? A few simple reasons, files are getting HUGE. It’s becoming difficult for our old 512-byte MFT records to store all the pointers to the different blocks that make up the files; especially when the files start getting fragmented or deduped. These new 4K file records allow for eight times as much data to be stored about these files in the MFT, helping to prevent the need to daisy chain multiple records to each other in order simply gather all the blocks of a file. If you’ve worked with Veeam and Windows dedupe, you’ve probably seen that they recommend every volume be formatted with the /L switch, which that turns on large file records. This is so that as the big backup files get deduped, the single record has more room to keep track of all the blocks without having to chain to other records.
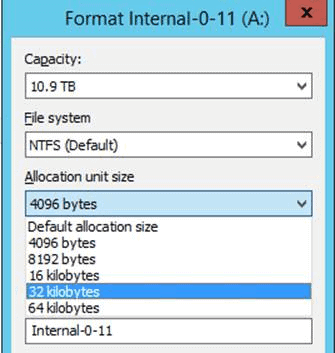
Another important thing to keep in mind with these mega files is your block size. Remember this is the size allocated for ANY new data write. In Windows it ranges from 4k to 64K. When does it matter? If you’re writing a reasonably large file (say 100gb) in 4k blocks, that’s 26 million blocks that make up that file. Twenty-six million blocks just to keep up with for that one file. If it’s written it in 64k blocks, though, it’s now only 1.6 million blocks to keep up with for that one file. This will make a massive difference for our index, a lot fewer blocks to potentially fragment, and fewer records to track when we dedupe.
“So let’s always do 4k file records and 64K block size, that way we’ll have fewer of these issues!”… of course, it’s not that simple. Think now in terms of lots of small files — for argument’s sake let’s use 10 million — ranging in size from 40K to 1MB. Those files, being so small, probably won’t be exceedingly fragmented or deduped due to their small size. If I have to allocate 4K for my indexes to all 10 million files, I’ve now used at least 38 gigabytes JUST for all of my file records. However, if I stick with the old 512 byte, it’s around an eighth of that size. Not a big loss in modern storage, but think of it more in terms of overhead: eight times as much MFT storage for the same data.
Now think of our block sizes; 64K blocks in this example. If my file is 40K, I waste 24K of storage because I have to write in 64K chunks even though it’s less than that minimum metric. If my data is 65K I now waste 63K of storage because it’s too big to fit in one block so I have to use two. Multiply that by 10,000,000 miles, and it adds up into appreciable storage.
So what’s the answer? It depends. During configuration, pay attention to your workload and what you plan to do with the storage. This is EXTREMELY important. This is (quite literally) the foundation for your entire storage. If you get it wrong and then move 17TB of data onto it, you’re stuck with it unless you have somewhere to move all that data off to, reformat and start over. Proper planning is key.